Ascoltando l '"effetto cocktail party" nel cervello
Alcune persone possono concentrarsi su un singolo oratore nonostante l'ambiente circostante oscuri la voce di una persona. L'ambiente può essere un'aula, un bar o un evento sportivo: l'abilità non è unica ed è stata descritta dagli psicologi come "effetto cocktail party".
Un nuovo sforzo di ricerca guidato da un neurochirurgo dell'Università della California - San Francisco e da un borsista post-dottorato si è concentrato sulla scoperta di come funziona l'udito selettivo nel cervello.
Edward Chang, M.D., e Nima Mesgarani, Ph.D., hanno lavorato con tre pazienti sottoposti a chirurgia cerebrale per grave epilessia.
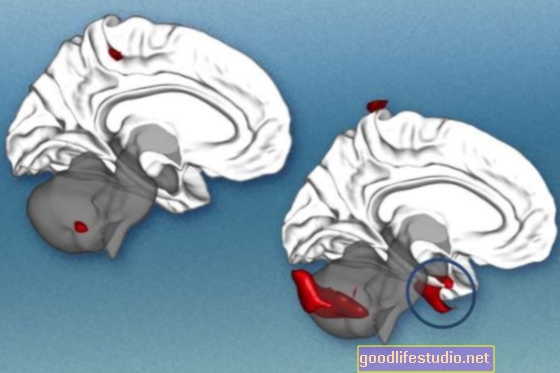
Parte di questo intervento chirurgico comporta l'individuazione delle parti del cervello responsabili delle convulsioni invalidanti. Questo esercizio prevede la mappatura dell'attività del cervello nell'arco di una settimana, con un sottile foglio di massimo 256 elettrodi posizionato sotto il cranio sulla superficie esterna del cervello o sulla corteccia. Gli elettrodi registrano l'attività nel lobo temporale, sede della corteccia uditiva.
Chang ha affermato che la capacità di registrare in sicurezza le registrazioni intracraniche ha fornito opportunità uniche per far avanzare la conoscenza fondamentale di come funziona il cervello.
"La combinazione di registrazioni cerebrali ad alta risoluzione e potenti algoritmi di decodifica apre una finestra sull'esperienza soggettiva della mente che non abbiamo mai visto prima", ha detto Chang.
Negli esperimenti, i pazienti hanno ascoltato due campioni di discorso riprodotti simultaneamente in cui frasi diverse erano pronunciate da diversi oratori. È stato chiesto loro di identificare le parole che hanno sentito pronunciare da uno dei due oratori.
Gli autori hanno quindi applicato nuovi metodi di decodifica per "ricostruire" ciò che i soggetti hanno sentito dall'analisi dei loro schemi di attività cerebrale.
Sorprendentemente, gli autori hanno scoperto che le risposte neurali nella corteccia uditiva riflettevano solo quelle dell'oratore mirato. Hanno scoperto che il loro algoritmo di decodifica poteva prevedere quale parlante e persino quali parole specifiche il soggetto stava ascoltando in base a quei modelli neurali. In altre parole, potevano capire quando l'attenzione dell'ascoltatore si era spostata su un altro oratore.
"L'algoritmo ha funzionato così bene che abbiamo potuto prevedere non solo le risposte corrette, ma anche quando hanno prestato attenzione alla parola sbagliata", ha detto Chang.
Le nuove scoperte mostrano che la rappresentazione del discorso nella corteccia non riflette solo l'intero ambiente acustico esterno, ma solo ciò che vogliamo o dobbiamo sentire veramente.
Rappresentano un importante progresso nella comprensione di come il cervello umano elabora il linguaggio, con implicazioni immediate per lo studio della menomazione durante l'invecchiamento, disturbo da deficit di attenzione, autismo e disturbi dell'apprendimento del linguaggio.
Inoltre, Chang afferma che un giorno potremmo essere in grado di utilizzare questa tecnologia per dispositivi neuroprotetici per decodificare le intenzioni e i pensieri di pazienti paralizzati che non possono comunicare.
La comprensione di come il nostro cervello è cablato per favorire alcuni segnali uditivi rispetto ad altri può incoraggiare nuovi approcci verso l'automazione e il miglioramento del modo in cui le interfacce elettroniche attivate dalla voce filtrano i suoni al fine di rilevare correttamente i comandi verbali.
Il metodo con cui il cervello può concentrarsi in modo così efficace su una singola voce è un'area di notevole interesse per le aziende che sviluppano dispositivi elettronici con interfacce vocali attive.
Sebbene le tecnologie di riconoscimento vocale che abilitano interfacce come Siri di Apple abbiano fatto molta strada negli ultimi anni, non sono neanche lontanamente sofisticate come il sistema vocale umano. Ad esempio, una persona normale può entrare in una stanza rumorosa e avere una conversazione privata con relativa facilità, come se tutte le altre voci nella stanza fossero state disattivate.
Il riconoscimento vocale, ha detto Mesgarani, un ingegnere con esperienza nella ricerca sul riconoscimento vocale automatico, è "qualcosa in cui gli esseri umani sono straordinariamente bravi, ma si scopre che l'emulazione automatica di questa abilità umana è estremamente difficile".
L'articolo di ricerca appare sulla rivista Natura.
Fonte: University of California, San Francisco (UCSF)